AI & Security: Introduction (Part 1)

In this blog series, I’m diving into the world of Large Language Models (LLMs) and their impact on security—both the benefits and the risks. If you’re anything like me, you’ve learned that nothing new comes without both sides of the coin; there’s always a mix of good and bad. For defenders, this means embracing the advantages while finding ways to mitigate the drawbacks.
But before we tackle the risks and rewards, let’s start with the basics. The goal of this article is to break down the fundamentals of LLMs in the simplest way possible, laying the groundwork for upcoming posts that will delve into their implications for IT security. Let’s get started.
Understanding Large Language Models
To really grasp what LLMs are, we’ll get hands-on. I recommend starting with HuggingFace.co, a platform loaded with tools and resources to help you explore LLMs. Get your environment set up there, and let’s take a closer look.
The basics
At their core, LLMs predict the next word in a sequence based on the context provided by the preceding words. How do they do that? By “reading the internet” and teaching themselves. This process involves a kind of “split-brain” approach: one part of the model reads a sentence (say, from Wikipedia), then removes a word, creating a “gap text.” The other “hemisphere” of the model tries to guess the missing word based on probability. If it matches the original word, that’s a win (think of it as digital dopamine); if not, it’s recorded as a miss. Through countless iterations, the model learns to predict words and form coherent sentences.
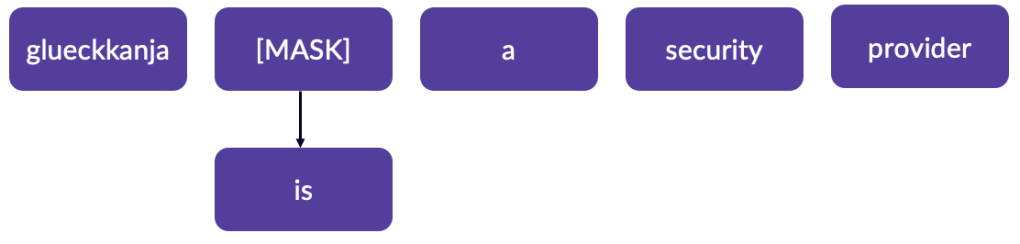
These gaps are referred to as “masks,” and because the model handles this process on its own, it’s known as “self-supervised learning.”
This pre-training phase gives the model a statistical grasp of language, but it’s not yet skilled at specific tasks. To improve, the model undergoes “transfer learning,” where it’s fine-tuned with supervised data.
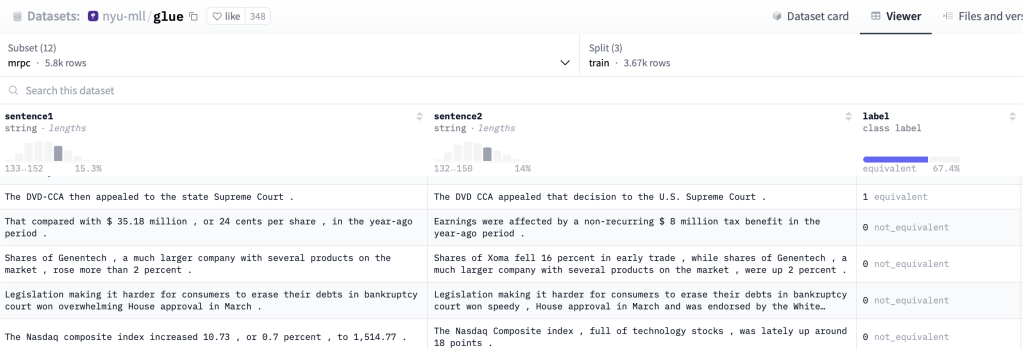
For example, the MRPC dataset contains 5,801 sentence pairs labeled as equivalent or not. Human annotators manually perform this labelling, teaching the model which sentences mean the same thing.

With this data, the model can generate content, and after being fine-tuned, it’s known as a Generative Pre-trained Transformer, or GPT for short.
Examples in Action
Once you’ve set up your environment on HuggingFace and followed their Natural Language Processing tutorial, you’ll get a sense of what these models can do. There are smaller modules called “pipelines” that utilize LLMs in real-time. For instance, a sentiment analysis pipeline can evaluate a sentence and determine whether it conveys a positive or negative sentiment. Try this: input a sentence like “glueckkanja is one of the best managed SOC providers in Europe.”:
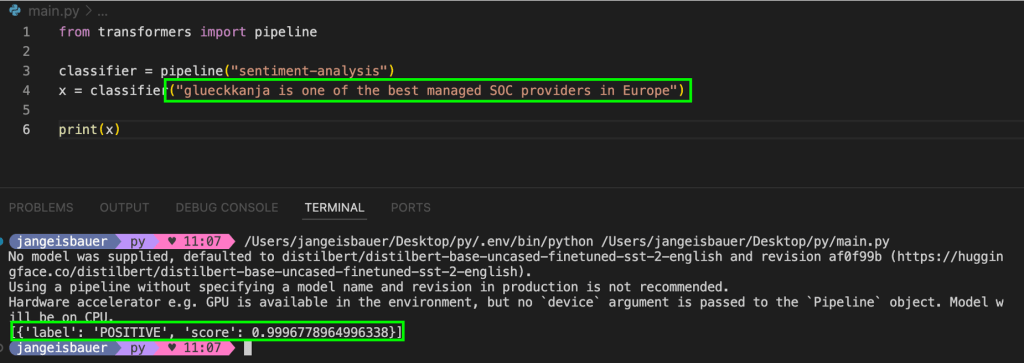
The model will likely indicate a 99% probability that the sentiment is positive. (sorry, I am using this example also in another context)
Another example is a classification pipeline that can tag an English sentence with the most appropriate label, such as “Business” or “Politics.”
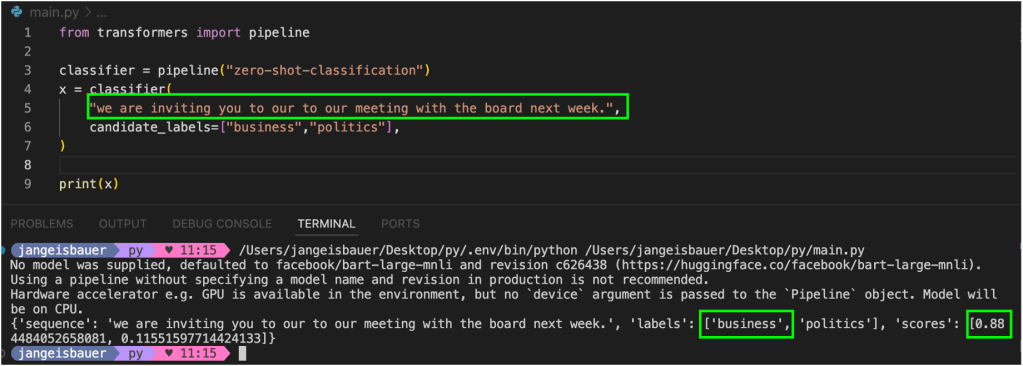
This capability comes from the model being trained on manually labeled data.
Grounding: Making the Models Smarter
At this point, the model “knows” what it learned during training. However, these training datasets are static—they only reflect knowledge up to the time they were created. In many cases, that won’t cut it. Take Microsoft 365 Copilot, for example; you wouldn’t want it to only recognize documents and emails from months ago. You need it to understand the email you received just three minutes ago.
To bridge this gap, search functionalities are integrated, such as using the Semantic Index and Microsoft Graph to enrich the model’s understanding with recent data. The process stays within the boundaries of the user’s security context, ensuring that sensitive information remains secure. We’ll cover jailbreak vulnerabilities and other security concerns in later posts.
Copilot Studio: Grounding in Action
To see how grounding works, let’s explore Copilot Studio.
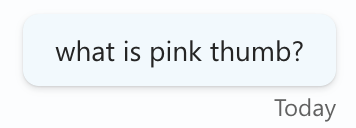
I’ve set up a Copilot for my website, which means the LLM is now “grounded” with data from the site. You can ask the Copilot questions about the content found there and get accurate answers.
Teaching the LLM to Chat
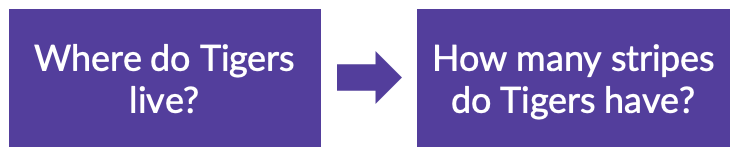
So far, we’ve seen how an LLM learns language fundamentals through self-supervised learning and then gets fine-tuned via supervised methods (like manual labelling). But even at this stage, it won’t be able to answer your questions. If you asked where tigers live, it might respond with a question instead.
To make LLMs capable of holding meaningful conversations, we use fine-tuning again—this time with instruction-based datasets. With that it learns how to answer questions:
You can browse through HuggingFace datasets to explore more of these examples. This helps the model understand how to follow instructions, making it capable of engaging in a chat-like format.
The Challenge of Truthfulness
Since LLMs are generative, they often try to make the most out of the data they’ve been trained on. It’s a tricky balance to strike between creating something new and preventing it from “lying”. When an LLM generates content that isn’t true, it’s called “hallucination“.
One promising solution is Retrieval-Augmented Generation (RAG), which integrates knowledge from external databases, allowing the LLM to fact-check its responses before presenting them to the user.
What’s Next?
Now that we’ve taken a peek under the hood of LLMs, we’re ready to tackle their challenges, risks, and opportunities in future posts. As we said at the beginning: there’s no good without the bad. Stay tuned as we explore both sides in this ongoing AI series.
